Convertire files DOCX o ODT in PDF a volte è indispensabile per ottenere PDF personalizzati con dati conservati negli archivi dal proprio applicativo. Ci sono molti modi per raggiungere questo obiettivo, i fattori decisivi che fanno protendere per l’una od l’altra soluzione sono le sorgenti dei dati, il tipo di documento da produrre e il livello di personalizzazione del documento da produrre.
Un cliente, recentemente, mi ha chiesto: Mauro come posso utilizzare un file DOCX o ODT come file template, aggiornarlo con dati prelevati dall’archivio gestito dall’applicativo e fornire in output un file PDF?
Come dicevo prima, ci sono diverse soluzioni per convertire DOCX in PDF, io ne ho scelta una in particolare che punta al disaccoppiamento applicativo e ragiona in un’ottica di reimpiego di servizi esterni all’applicativo stesso. Questo approccio consente di avere un applicativo più snello in termini di codice e delega ad una terza parte, autonoma, la realizzazione di un’attività non propria dell’applicativo.
Segue uno schema che mostra il confronto tra la modalità classica/monolitica e la soluzione a compiti ripartiti/suddivisi.
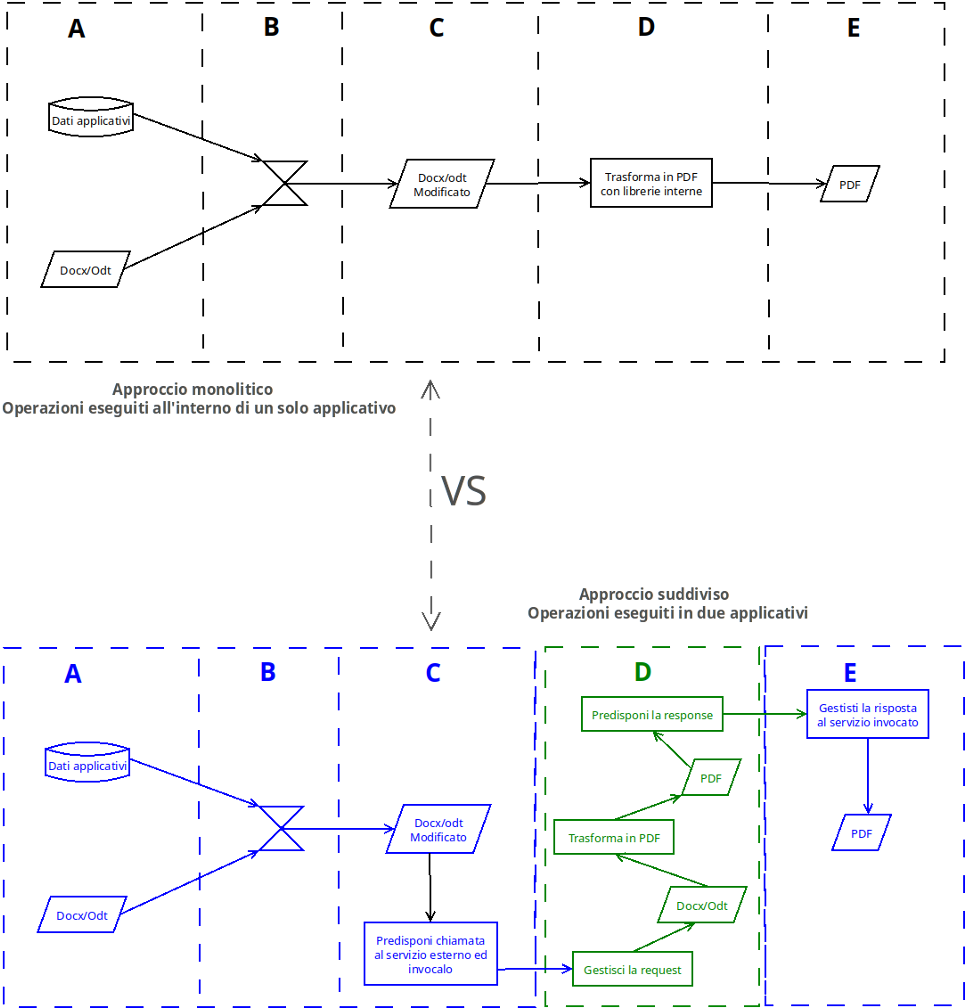
Soluzione suddivisa
La soluzione indicata come suddivisa si appoggia sull’impiego di un servizio che prende in pasto il file binario DOCX od ODT e restituisce un PDF, tutto attraverso una chiamata HTTP/REST.
Questo servizio si implementa velocemente con l’impiego di codice disponibile nel mondo open source.
Per realizzare l’immagine docker necessaria a tirar su il servizio REST di conversione, è sufficiente collegarsi al seguente indirizzo https://github.com/EugenMayer/officeconverter e seguire le istruzioni. L’aspetto positivo di questa soluzione risiede nel fatto che sono impiegati componenti open source di ottima qualità, come LibreOffice che consente di ottenere PDF di buona qualità.
In pratica … da DOCX o ODT a PDF
Il file docker-compose da impiegare per far partire una istanza di questa immagine:
version: "3.5" services: jodconverterrest: image: eugenmayer/jodconverter:rest restart: always container_name: jodconverterrest ports: - "0.0.0.0:8080:8080" volumes: - "./app:/etc/app:ro" - "/data/repository/jodconverterrest:/tmp:rw"
In questa configurazione è previsto che vengano fornite due aree di lavoro al container:
- una montata nel punto /etc/app che conterrà il file application.properties usato dall’applicativo realizzato in tecnologia spring-boot
- un’altra montata nel punto /tmp che servirà per contenere i file temporanei impiegati dall’applicativo realizzato in tecnologia spring-boot
Riporto un esempio del file application.properties a titolo di esempio:
jodconverter.local.port-numbers: 2002, 2003 jodconverter.local.working-dir: /tmp spring.servlet.multipart.max-file-size: 50MB spring.servlet.multipart.max-request-size: 50MB server.port=8080
Una volta avviato il servizio questo potrà essere raggiungibile sulla porta indicata, da un qualsiasi applicativo scritto adeguatamente per accedere al servizio ed ottenere la conversione desiderata.
Riporto un’estratto del codice JAVA che consente di invocare questa chiamata HTTP/REST convertendo il testo DOCX o ODT in PDF.
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.io.OutputStreamWriter;
import java.io.PrintWriter;
import java.net.HttpURLConnection;
import java.net.MalformedURLException;
import java.net.URL;
import java.net.URLConnection;
...
private final static String CRLF = "\r\n";
static byte[] convertDocToPDF(byte[] input, String filename, String contentype, URL url) throws MalformedURLException, IOException{
URLConnection connection = url.openConnection();
connection.setDoOutput(true);
String boundary = Long.toHexString(System.currentTimeMillis());
connection.setRequestProperty("Content-Type", "multipart/form-data; boundary=" + boundary);
OutputStream output = connection.getOutputStream();
PrintWriter writer = new PrintWriter(new OutputStreamWriter(output), true);
writer.append("--" + boundary).append(CRLF);
writer.append("Content-Disposition: form-data; name=\"data\"; filename=\"" + filename + "\"").append(CRLF);
writer.append("Content-Type: " + contentype).append(CRLF);
writer.append("Content-Transfer-Encoding: binary").append(CRLF);
writer.append(CRLF).flush();
output.write(input);
output.flush();
writer.append(CRLF).flush();
writer.append("--" + boundary + "--").append(CRLF).flush();
HttpURLConnection httpConnection = (HttpURLConnection)connection;
int responseCode = httpConnection.getResponseCode();
InputStream response = httpConnection.getInputStream();
byte[] result = response.readAllBytes();
return result;
}
...
L’url da impiegare per accedere alla funzionalità di conversione sarà http://<HOST>:<PORT>/lool/convert-to/pdf
Analizzando il codice si evince che all’interno del nostro applicativo è necessario definire un semplice metodo statico che prenda in pasto:
– il file binario DOCX o ODT;
– il nome del file in input;
– il mimetype;
– l’url da contattare per ottenere la conversione.
Come risposta otterremo un file binario in PDF.
Così, con pochissime righe di codice, abbiamo aggiunto la funzionalità di conversione di un documento DOCX o ODT in PDF, all’interno del nostro applicativo.
Questo approccio consente di avere più applicativi che impiegano la medesima funzionalità di generazione del PDF:
– appoggio ad una risorsa esterna, configurabile anche in alta affidabilità;
– impatto minimo sul codice da mantenere e gestire:
– riduzione notevole del numero di dipendenze come jar da includere all’interno del nostro applicativo.